一,基础应用
(1)创建createDataFrame
package com.hollysys.spark
import java.util
import org.apache.spark.sql.types._
import org.apache.spark.sql.{Row, SQLContext, SparkSession}
object CreateDataFrameTest {
def main(args: Array[String]): Unit = {
val spark = SparkSession
.builder()
.appName(this.getClass.getSimpleName).master("local")
.getOrCreate()
//通过Seq生成
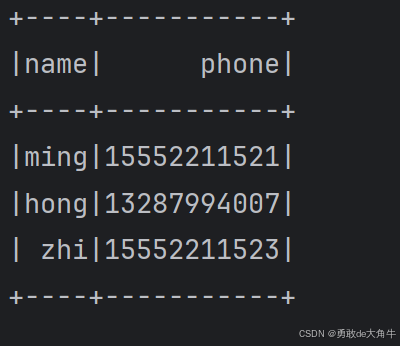
val df = spark.createDataFrame(Seq(
("ming", 20, 15552211521L),
("hong", 19, 13287994007L),
("zhi", 21, 15552211523L)
)) toDF("name", "age", "phone")
df.show()
//动态创建schema
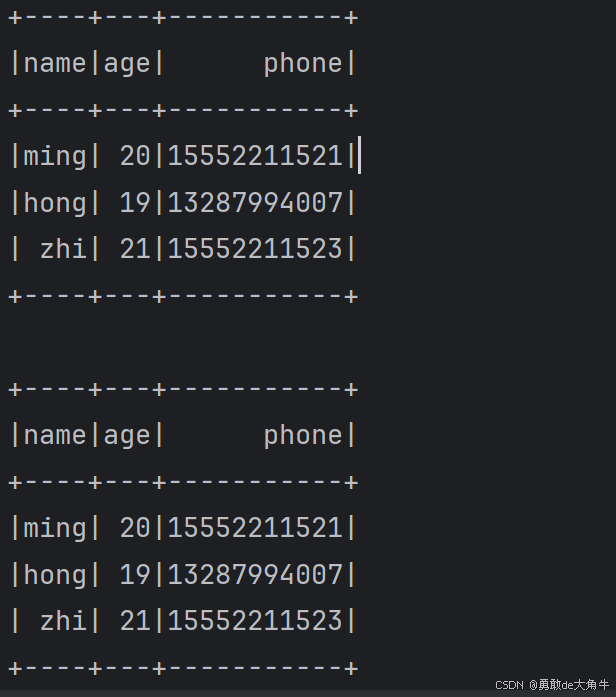
val schema = StructType(List(
StructField("name", StringType, true),
StructField("age", IntegerType, true),
StructField("phone", LongType, true)
))
val dataList = new util.ArrayList[Row]()
dataList.add(Row("ming",20,15552211521L))
dataList.add(Row("hong",19,13287994007L))
dataList.add(Row("zhi",21,15552211523L))
spark.createDataFrame(dataList,schema).show()
}
}
运行效果:
如果对此感兴趣,请查询链接:Spark创建DataFrame的几种方式_spark.createdataframe-CSDN博客
(2) select和selectExpr方法
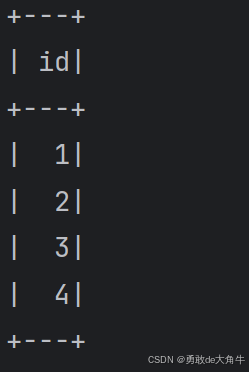
//selece方法 import org.apache.spark.sql.SparkSession object select { def main(args: Array[String]): Unit = { val spark = SparkSession .builder() //创建Spark会话 .appName("Spark SQL basic example") //设置会话名称 .master("local") //设置本地模式 .getOrCreate() //创建会话变量 val rdd = spark.sparkContext.parallelize(Array(1,2,3,4)) import spark.implicits._ val df = rdd.toDF("id") df.select("id").show() //选择“id”列 } }//selectExpr方法
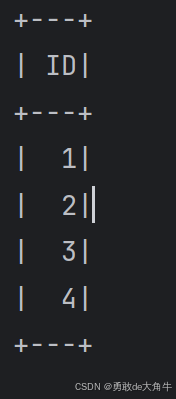
import org.apache.spark.sql.SparkSession object select { def main(args: Array[String]): Unit = { val spark = SparkSession .builder() //创建Spark会话 .appName("Spark SQL basic example") //设置会话名称 .master("local") //设置本地模式 .getOrCreate() //创建会话变量 val rdd = spark.sparkContext.parallelize(Array(1,2,3,4)) import spark.implicits._ val df = rdd.toDF("id") df.selectExpr("id as ID").show() //设置了一个别名ID } }
分开分别运行后,查看运行结果:
select方法 selectExpr方法
(3)collect方法
import org.apache.spark.sql.SparkSession
object collect {
def main(args: Array[String]): Unit = {
val spark = SparkSession
.builder() //创建Spark会话
.appName("Spark SQL basic example") //设置会话名称
.master("local") //设置本地模式
.getOrCreate() //创建会话变量
val rdd = spark.sparkContext.parallelize(Array(1,2,3,4))
import spark.implicits._
val df = rdd.toDF("id")
val arr = df.collect()
println(arr.mkString("Array(", ", ", ")"))
}
}
运行结果:
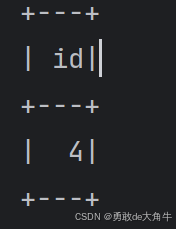
(4)DataFrame计算行数count方法
import org.apache.spark.sql.SparkSession
object count {
def main(args: Array[String]): Unit = {
val spark = SparkSession
.builder() //创建Spark会话
.appName("Spark SQL basic example") //设置会话名称
.master("local") //设置本地模式
.getOrCreate() //创建会话变量
val rdd = spark.sparkContext.parallelize(Array(1,2,3,4))
import spark.implicits._
val df = rdd.toDF("id")
println(df.count()) //计算行数
}
}
运行结果
(5)过滤数据的filter方法
import org.apache.spark.sql.SparkSession
object fliter {
def main(args: Array[String]): Unit = {
val spark = SparkSession
.builder() //创建Spark会话
.appName("Spark SQL basic example") //设置会话名称
.master("local") //设置本地模式
.getOrCreate() //创建会话变量
val rdd = spark.sparkContext.parallelize(Array(1,2,3,4))
import spark.implicits._
val df = rdd.toDF("id")
val df2 = df.filter("id>3")//过滤id列大于3的数据(行)或 _ >= 3
println(df2.cache().show()) //打印结果
}
}
运行效果
(6)以整体数据为单位操作数据的flatMap方法
import org.apache.spark.sql.SparkSession
object flatmap {
def main(args: Array[String]): Unit = {
val spark = SparkSession
.builder() //创建Spark会话
.appName("Spark SQL basic example") //设置会话名称
.master("local") //设置本地模式
.getOrCreate() //创建会话变量
val rdd = spark.sparkContext.parallelize(Seq("hello!spark", "hello!hadoop"))
import spark.implicits._
val df = rdd.toDF("id")
val x = df.flatMap(x => x.toString().split("!")).collect()
println(x.mkString("Array(", ", ", ")"))
}
}
运行效果

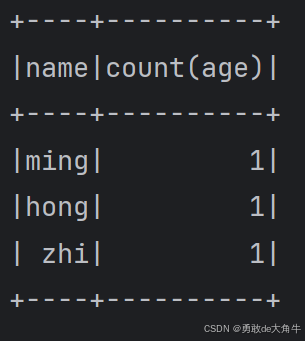
(7)分组数据的groupBy和agg方法
import org.apache.spark.sql.SparkSession
object GroupByExample {
def main(args: Array[String]): Unit = {
val spark = SparkSession
.builder()
.appName("Spark SQL basic example")
.master("local")
.getOrCreate()
// 导入隐式转换,获取默认的编码器
import spark.implicits._
// 创建 JSON 字符串数组的 Dataset
val jsonDataSet = spark.createDataset(Array(
"{\"name\":\"ming\",\"age\":20,\"phone\":15552211521}",
"{\"name\":\"hong\", \"age\":19,\"phone\":13287994007}",
"{\"name\":\"zhi\", \"age\":21,\"phone\":15552211523}"
))
// 将 JSON 数据集转换为 DataFrame
val jsonDataSetDf = spark.read.json(jsonDataSet)
// 显示 DataFrame 的内容
jsonDataSetDf.groupBy("name").agg("age" -> "count").show()
spark.stop()
}
}
运行效果:
(8)删除数据集中某列的drop方法
import org.apache.spark.sql.SparkSession
object GroupByExample {
def main(args: Array[String]): Unit = {
val spark = SparkSession
.builder()
.appName("Spark SQL basic example")
.master("local")
.getOrCreate()
// 导入隐式转换,获取默认的编码器
import spark.implicits._
// 创建 JSON 字符串数组的 Dataset
val jsonDataSet = spark.createDataset(Array(
"{\"name\":\"ming\",\"age\":20,\"phone\":15552211521}",
"{\"name\":\"hong\", \"age\":19,\"phone\":13287994007}",
"{\"name\":\"zhi\", \"age\":21,\"phone\":15552211523}"
))
// 将 JSON 数据集转换为 DataFrame
val jsonDataSetDf = spark.read.json(jsonDataSet)
// 显示 DataFrame 的内容
jsonDataSetDf.drop("age").show()
//删除age列
spark.stop()
}
}