Elasticsearch 系列文章
1、介绍lucene的功能以及建立索引、搜索单词、搜索词语和搜索句子四个示例实现
2、Elasticsearch7.6.1基本介绍、2种部署方式及验证、head插件安装、分词器安装及验证
3、Elasticsearch7.6.1信息搜索示例(索引操作、数据操作-添加、删除、导入等、数据搜索及分页)
4、Elasticsearch7.6.1 Java api操作ES(CRUD、两种分页方式、高亮显示)和Elasticsearch SQL详细示例
5、Elasticsearch7.6.1 filebeat介绍及收集kafka日志到es示例
6、Elasticsearch7.6.1、logstash、kibana介绍及综合示例(ELK、grok插件)
7、Elasticsearch7.6.1收集nginx日志及监测指标示例
8、Elasticsearch7.6.1收集mysql慢查询日志及监控
9、Elasticsearch7.6.1 ES与HDFS相互转存数据-ES-Hadoop
本文简单的介绍了java api操作Elasticsearch和Elasticsearch SQL的详细示例。
本文依赖es环境可用。
本文分为2个部分,及java api操作es和es sql的详细使用示例。
一、java api操作ES
使用一个JobService类来实现上一篇文章中的示例,此处用RESTFul完成的操作
需要增加一个日志文件配置
官网API地址:https://www.elastic.co/guide/en/elasticsearch/client/java-rest/7.6/java-rest-high.html
1、pom.xml
<dependencies>
<!-- ES的高阶的客户端API -->
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-high-level-client</artifactId>
<version>7.6.1</version>
</dependency>
<!-- 阿里巴巴出品的一款将Java对象转换为JSON、将JSON转换为Java对象的库 -->
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.62</version>
</dependency>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-core</artifactId>
<version>2.11.1</version>
</dependency>
</dependencies>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
2、日志配置
3、bean
在id字段上添加一个 @JSONField注解,并配置注解的serialize为false,表示该字段无需转换为JSON,因为它就是文档的唯一ID。
import com.alibaba.fastjson.JSONObject;
import com.alibaba.fastjson.annotation.JSONField;
import lombok.Data;
/**
* @author chenw
*
*/
@Data
public class JobDetail {
@JSONField(serialize = false)
private long id;
private String area;
private String exp;
private String edu;
private String salary;
private String job_type;
private String cmp;
private String pv;
private String title;
private String jd;
@Override
public String toString() {
// 使用FastJSON将一个对象直接转换为JSON字符串
return id + ":" + JSONObject.toJSONString(this);
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
4、service及实现
- 服务接口
import java.io.IOException;
import java.util.List;
import java.util.Map;
import org.example.bean.JobDetail;
/**
* @author chenw
*
*/
public interface JobFullTextService {
// 添加一个职位数据
void add(JobDetail jobDetail) throws IOException;
// 根据ID检索指定职位数据
JobDetail findById(long id) throws IOException;
// 修改职位薪资
void update(JobDetail jobDetail) throws IOException;
// 根据ID删除指定位置数据
void deleteById(long id) throws IOException;
// 根据关键字检索数据
List<JobDetail> searchByKeywords(String keywords) throws IOException;
// 分页检索
Map<String, Object> searchByPage(String keywords, int pageNum, int pageSize) throws IOException;
// scroll分页解决深分页问题
Map<String, Object> searchByScrollPage(String keywords, String scrollId, int pageSize) throws IOException;
// 关闭ES连接
void close() throws IOException;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 接口实现
import java.io.IOException;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import org.apache.http.HttpHost;
import org.elasticsearch.action.delete.DeleteRequest;
import org.elasticsearch.action.get.GetRequest;
import org.elasticsearch.action.get.GetResponse;
import org.elasticsearch.action.index.IndexRequest;
import org.elasticsearch.action.search.SearchRequest;
import org.elasticsearch.action.search.SearchResponse;
import org.elasticsearch.action.search.SearchScrollRequest;
import org.elasticsearch.action.update.UpdateRequest;
import org.elasticsearch.client.RequestOptions;
import org.elasticsearch.client.RestClient;
import org.elasticsearch.client.RestClientBuilder;
import org.elasticsearch.client.RestHighLevelClient;
import org.elasticsearch.common.text.Text;
import org.elasticsearch.common.unit.TimeValue;
import org.elasticsearch.common.xcontent.XContentType;
import org.elasticsearch.index.query.MultiMatchQueryBuilder;
import org.elasticsearch.index.query.QueryBuilders;
import org.elasticsearch.search.SearchHit;
import org.elasticsearch.search.builder.SearchSourceBuilder;
import org.elasticsearch.search.fetch.subphase.highlight.HighlightBuilder;
import org.elasticsearch.search.fetch.subphase.highlight.HighlightField;
import org.example.bean.JobDetail;
import org.example.service.JobFullTextService;
import com.alibaba.fastjson.JSONObject;
/**
* @author chenw
*
*/
public class JobFullTextServiceImpl implements JobFullTextService {
// 索引库的名字
private static final String JOB_IDX = "job_idx";
private RestHighLevelClient restHighLevelClient;
public JobFullTextServiceImpl() {
// 建立与ES的连接
// 1. 使用RestHighLevelClient构建客户端连接。
// 2. 基于RestClient.builder方法来构建RestClientBuilder
// 3. 用HttpHost来添加ES的节点
RestClientBuilder restClientBuilder = RestClient.builder(
new HttpHost("server1", 9200, "http"),
new HttpHost("server2", 9200, "http"),
new HttpHost("server3", 9200, "http"));
restHighLevelClient = new RestHighLevelClient(restClientBuilder);
}
/**
* @param args
*/
public static void main(String[] args) {
}
@Override
public void add(JobDetail jobDetail) throws IOException {
// 1. 构建IndexRequest对象,用来描述ES发起请求的数据。
IndexRequest indexRequest = new IndexRequest(JOB_IDX);
// 2. 设置文档ID。
indexRequest.id(jobDetail.getId() + "");
// 3. 使用FastJSON将实体类对象转换为JSON。
String json = JSONObject.toJSONString(jobDetail);
// 4. 使用IndexRequest.source方法设置文档数据,并设置请求的数据为JSON格式。
indexRequest.source(json, XContentType.JSON);
// 5. 使用ES High level client调用index方法发起请求,将一个文档添加到索引中。
restHighLevelClient.index(indexRequest, RequestOptions.DEFAULT);
}
@Override
public JobDetail findById(long id) throws IOException {
// 1. 构建GetRequest请求。
GetRequest getRequest = new GetRequest(JOB_IDX, id + "");
// 2. 使用RestHighLevelClient.get发送GetRequest请求,并获取到ES服务器的响应。
GetResponse getResponse = restHighLevelClient.get(getRequest, RequestOptions.DEFAULT);
// 3. 将ES响应的数据转换为JSON字符串
String json = getResponse.getSourceAsString();
// 4. 并使用FastJSON将JSON字符串转换为JobDetail类对象
JobDetail jobDetail = JSONObject.parseObject(json, JobDetail.class);
// 5. 记得:单独设置ID
jobDetail.setId(id);
return jobDetail;
}
@Override
public void update(JobDetail jobDetail) throws IOException {
// 1. 判断对应ID的文档是否存在
// a) 构建GetRequest
GetRequest getRequest = new GetRequest(JOB_IDX, jobDetail.getId() + "");
// b) 执行client的exists方法,发起请求,判断是否存在
boolean exists = restHighLevelClient.exists(getRequest, RequestOptions.DEFAULT);
if (exists) {
// 2. 构建UpdateRequest请求
UpdateRequest updateRequest = new UpdateRequest(JOB_IDX, jobDetail.getId() + "");
// 3. 设置UpdateRequest的文档,并配置为JSON格式
updateRequest.doc(JSONObject.toJSONString(jobDetail), XContentType.JSON);
// 4. 执行client发起update请求
restHighLevelClient.update(updateRequest, RequestOptions.DEFAULT);
}
}
@Override
public void deleteById(long id) throws IOException {
// 1. 构建delete请求
DeleteRequest deleteRequest = new DeleteRequest(JOB_IDX, id + "");
// 2. 使用RestHighLevelClient执行delete请求
restHighLevelClient.delete(deleteRequest, RequestOptions.DEFAULT);
}
@Override
public List<JobDetail> searchByKeywords(String keywords) throws IOException {
/// 1.构建SearchRequest检索请求
// 专门用来进行全文检索、关键字检索的API
SearchRequest searchRequest = new SearchRequest(JOB_IDX);
// 2.创建一个SearchSourceBuilder专门用于构建查询条件
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
// 3.使用QueryBuilders.multiMatchQuery构建一个查询条件(搜索title、jd),并配置到SearchSourceBuilder
MultiMatchQueryBuilder multiMatchQueryBuilder = QueryBuilders.multiMatchQuery(keywords, "title", "jd");
// 将查询条件设置到查询请求构建器中
searchSourceBuilder.query(multiMatchQueryBuilder);
// 4.调用SearchRequest.source将查询条件设置到检索请求
searchRequest.source(searchSourceBuilder);
// 5.执行RestHighLevelClient.search发起请求
SearchResponse searchResponse = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
SearchHit[] hitArray = searchResponse.getHits().getHits();
// 6.遍历结果
ArrayList<JobDetail> jobDetailArrayList = new ArrayList<>();
for (SearchHit documentFields : hitArray) {
// 1)获取命中的结果
String json = documentFields.getSourceAsString();
// 2)将JSON字符串转换为对象
JobDetail jobDetail = JSONObject.parseObject(json, JobDetail.class);
// 3)使用SearchHit.getId设置文档ID
jobDetail.setId(Long.parseLong(documentFields.getId()));
jobDetailArrayList.add(jobDetail);
}
return jobDetailArrayList;
}
@Override
public Map<String, Object> searchByPage(String keywords, int pageNum, int pageSize) throws IOException {
// 1.构建SearchRequest检索请求
// 专门用来进行全文检索、关键字检索的API
SearchRequest searchRequest = new SearchRequest(JOB_IDX);
// 2.创建一个SearchSourceBuilder专门用于构建查询条件
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
// 3.使用QueryBuilders.multiMatchQuery构建一个查询条件(搜索title、jd),并配置到SearchSourceBuilder
MultiMatchQueryBuilder multiMatchQueryBuilder = QueryBuilders.multiMatchQuery(keywords, "title", "jd");
// 将查询条件设置到查询请求构建器中
searchSourceBuilder.query(multiMatchQueryBuilder);
// 每页显示多少条
searchSourceBuilder.size(pageSize);
// 设置从第几条开始查询
searchSourceBuilder.from((pageNum - 1) * pageSize);
// 4.调用SearchRequest.source将查询条件设置到检索请求
searchRequest.source(searchSourceBuilder);
// 5.执行RestHighLevelClient.search发起请求
SearchResponse searchResponse = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
SearchHit[] hitArray = searchResponse.getHits().getHits();
// 6.遍历结果
ArrayList<JobDetail> jobDetailArrayList = new ArrayList<>();
for (SearchHit documentFields : hitArray) {
// 1)获取命中的结果
String json = documentFields.getSourceAsString();
// 2)将JSON字符串转换为对象
JobDetail jobDetail = JSONObject.parseObject(json, JobDetail.class);
// 3)使用SearchHit.getId设置文档ID
jobDetail.setId(Long.parseLong(documentFields.getId()));
jobDetailArrayList.add(jobDetail);
}
// 8. 将结果封装到Map结构中(带有分页信息)
// a) total -> 使用SearchHits.getTotalHits().value获取到所有的记录数
// b) content -> 当前分页中的数据
long totalNum = searchResponse.getHits().getTotalHits().value;
HashMap hashMap = new HashMap();
hashMap.put("total", totalNum);
hashMap.put("content", jobDetailArrayList);
return hashMap;
}
@Override
public Map<String, Object> searchByScrollPage(String keywords, String scrollId, int pageSize) throws IOException {
SearchResponse searchResponse = null;
if (scrollId == null) {
// 1.构建SearchRequest检索请求
// 专门用来进行全文检索、关键字检索的API
SearchRequest searchRequest = new SearchRequest(JOB_IDX);
// 2.创建一个SearchSourceBuilder专门用于构建查询条件
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
// 3.使用QueryBuilders.multiMatchQuery构建一个查询条件(搜索title、jd),并配置到SearchSourceBuilder
MultiMatchQueryBuilder multiMatchQueryBuilder = QueryBuilders.multiMatchQuery(keywords, "title", "jd");
// 将查询条件设置到查询请求构建器中
searchSourceBuilder.query(multiMatchQueryBuilder);
// 设置高亮
HighlightBuilder highlightBuilder = new HighlightBuilder();
highlightBuilder.field("title");
highlightBuilder.field("jd");
highlightBuilder.preTags("<font color='red'>");
highlightBuilder.postTags("</font>");
// 给请求设置高亮
searchSourceBuilder.highlighter(highlightBuilder);
// 每页显示多少条
searchSourceBuilder.size(pageSize);
// 4.调用SearchRequest.source将查询条件设置到检索请求
searchRequest.source(searchSourceBuilder);
// --------------------------
// 设置scroll查询
// --------------------------
searchRequest.scroll(TimeValue.timeValueMinutes(5));
// 5.执行RestHighLevelClient.search发起请求
searchResponse = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
}
// 第二次查询的时候,直接通过scroll id查询数据
else {
SearchScrollRequest searchScrollRequest = new SearchScrollRequest(scrollId);
searchScrollRequest.scroll(TimeValue.timeValueMinutes(5));
// 使用RestHighLevelClient发送scroll请求
searchResponse = restHighLevelClient.scroll(searchScrollRequest, RequestOptions.DEFAULT);
}
// --------------------------
// 迭代ES响应的数据
// --------------------------
SearchHit[] hitArray = searchResponse.getHits().getHits();
// 6.遍历结果
ArrayList<JobDetail> jobDetailArrayList = new ArrayList<>();
for (SearchHit documentFields : hitArray) {
// 1)获取命中的结果
String json = documentFields.getSourceAsString();
// 2)将JSON字符串转换为对象
JobDetail jobDetail = JSONObject.parseObject(json, JobDetail.class);
// 3)使用SearchHit.getId设置文档ID
jobDetail.setId(Long.parseLong(documentFields.getId()));
jobDetailArrayList.add(jobDetail);
// 设置高亮的一些文本到实体类中
// 封装了高亮
Map<String, HighlightField> highlightFieldMap = documentFields.getHighlightFields();
HighlightField titleHL = highlightFieldMap.get("title");
HighlightField jdHL = highlightFieldMap.get("jd");
if (titleHL != null) {
// 获取指定字段的高亮片段
Text[] fragments = titleHL.getFragments();
// 将这些高亮片段拼接成一个完整的高亮字段
StringBuilder builder = new StringBuilder();
for (Text text : fragments) {
builder.append(text);
}
// 设置到实体类中
jobDetail.setTitle(builder.toString());
}
if (jdHL != null) {
// 获取指定字段的高亮片段
Text[] fragments = jdHL.getFragments();
// 将这些高亮片段拼接成一个完整的高亮字段
StringBuilder builder = new StringBuilder();
for (Text text : fragments) {
builder.append(text);
}
// 设置到实体类中
jobDetail.setJd(builder.toString());
}
}
// 8. 将结果封装到Map结构中(带有分页信息)
// a) total -> 使用SearchHits.getTotalHits().value获取到所有的记录数
// b) content -> 当前分页中的数据
long totalNum = searchResponse.getHits().getTotalHits().value;
HashMap hashMap = new HashMap();
hashMap.put("scroll_id", searchResponse.getScrollId());
hashMap.put("content", jobDetailArrayList);
return hashMap;
}
@Override
public void close() throws IOException {
restHighLevelClient.close();
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
- 148
- 149
- 150
- 151
- 152
- 153
- 154
- 155
- 156
- 157
- 158
- 159
- 160
- 161
- 162
- 163
- 164
- 165
- 166
- 167
- 168
- 169
- 170
- 171
- 172
- 173
- 174
- 175
- 176
- 177
- 178
- 179
- 180
- 181
- 182
- 183
- 184
- 185
- 186
- 187
- 188
- 189
- 190
- 191
- 192
- 193
- 194
- 195
- 196
- 197
- 198
- 199
- 200
- 201
- 202
- 203
- 204
- 205
- 206
- 207
- 208
- 209
- 210
- 211
- 212
- 213
- 214
- 215
- 216
- 217
- 218
- 219
- 220
- 221
- 222
- 223
- 224
- 225
- 226
- 227
- 228
- 229
- 230
- 231
- 232
- 233
- 234
- 235
- 236
- 237
- 238
- 239
- 240
- 241
- 242
- 243
- 244
- 245
- 246
- 247
- 248
- 249
- 250
- 251
- 252
- 253
- 254
- 255
- 256
- 257
- 258
- 259
- 260
- 261
- 262
- 263
- 264
- 265
- 266
- 267
- 268
- 269
- 270
- 271
- 272
- 273
- 274
- 275
- 276
- 277
- 278
- 279
- 280
- 281
- 282
- 283
- 284
- 285
- 286
- 287
- 288
- 289
- 290
- 291
- 292
- 293
- 294
- 295
- 296
- 297
- 298
- 299
- 300
- 301
- 302
- 303
- 304
- 305
- 306
- 307
- 308
- 309
- 310
- 311
- 312
- 313
- 314
- 315
- 316
- 317
- 318
- 319
- 320
- 321
- 322
- 323
- 324
- 325
- 326
- 327
- 328
- 329
- 330
- 331
- 332
- 333
- 334
- 335
- 336
- 337
- 338
- 339
- 340
- 341
- 342
- 343
- 344
- 345
- 346
- 347
5、验证
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
import java.util.Map;
import org.example.bean.JobDetail;
import org.example.service.JobFullTextService;
import org.example.service.impl.JobFullTextServiceImpl;
import org.junit.After;
import org.junit.Before;
import org.junit.Test;
/**
* @author chenw
*
*/
public class JobFullTextServiceTest {
private JobFullTextService jobFullTextService;
@Before
public void beforeTest() {
jobFullTextService = new JobFullTextServiceImpl();
}
@Test
public void addTest() throws IOException {
JobDetail jobDetail = new JobDetail();
jobDetail.setId(1);
jobDetail.setArea("江苏省-南京市");
jobDetail.setCmp("Elasticsearch大学");
jobDetail.setEdu("本科及以上");
jobDetail.setExp("一年工作经验");
jobDetail.setTitle("大数据工程师");
jobDetail.setJob_type("全职");
jobDetail.setPv("1700次浏览");
jobDetail.setJd("会Hadoop就行");
jobDetail.setSalary("5-9千/月");
jobFullTextService.add(jobDetail);
}
@Test
public void getTest() throws IOException {
System.out.println(jobFullTextService.findById(1));
}
@Test
public void updateTest() throws IOException {
JobDetail jobDetail = jobFullTextService.findById(1);
jobDetail.setTitle("大数据巨牛开发工程师");
jobDetail.setSalary("10W飘20W/月");
jobFullTextService.update(jobDetail);
System.out.println(jobFullTextService.findById(1));
}
@Test
public void deleteTest() throws IOException {
jobFullTextService.deleteById(1);
// 执行下句会出现空指针异常
System.out.println(jobFullTextService.findById(1));
}
@Test
public void searchTest() throws IOException {
List<JobDetail> jobDetailList = jobFullTextService.searchByKeywords("flink");
for (JobDetail jobDetail : jobDetailList) {
System.out.println(jobDetail);
}
}
@Test
public void searchByPageTest() throws IOException {
Map<String, Object> resultMap = jobFullTextService.searchByPage("hbase", 1, 3);
System.out.println("一共查询到:" + resultMap.get("total").toString());
ArrayList<JobDetail> content = (ArrayList<JobDetail>) resultMap.get("content");
for (JobDetail jobDetail : content) {
System.out.println(jobDetail);
}
}
@Test
public void searchByScrollPageTest1() throws IOException {
Map<String, Object> resultMap = jobFullTextService.searchByScrollPage("spark", null, 10);
//scroll_id:DXF1ZXJ5QW5kRmV0Y2gBAAAAAAAAABgWTnFna0I1V2ZRbkNHTXlSbl9YTTF2UQ==
System.out.println("scroll_id:" + resultMap.get("scroll_id").toString());
ArrayList<JobDetail> content = (ArrayList<JobDetail>) resultMap.get("content");
for (JobDetail jobDetail : content) {
System.out.println(jobDetail);
}
}
@Test
public void searchByScrollPageTest2() throws IOException {
Map<String, Object> resultMap = jobFullTextService.searchByScrollPage("spark", "DXF1ZXJ5QW5kRmV0Y2gBAAAAAAAAABgWTnFna0I1V2ZRbkNHTXlSbl9YTTF2UQ==", 10);
System.out.println("scroll_id:" + resultMap.get("scroll_id").toString());
ArrayList<JobDetail> content = (ArrayList<JobDetail>)resultMap.get("content");
for (JobDetail jobDetail : content) {
System.out.println(jobDetail);
}
}
@After
public void afterTest() throws IOException {
jobFullTextService.close();
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
二、Elasticsearch SQL
Elasticsearch SQL允许执行类SQL的查询,可以使用REST接口、命令行或者是JDBC,都可以使用SQL来进行数据的检索和数据的聚合。
Elasticsearch SQL特点:
本地集成:Elasticsearch SQL是专门为Elasticsearch构建的。每个SQL查询都根据底层存储对相关节点有效执行。
没有额外的要求: 不依赖其他的硬件、进程、运行时库,Elasticsearch SQL可以直接运行在Elasticsearch集群上
轻量且高效:像SQL那样简洁、高效地完成查询
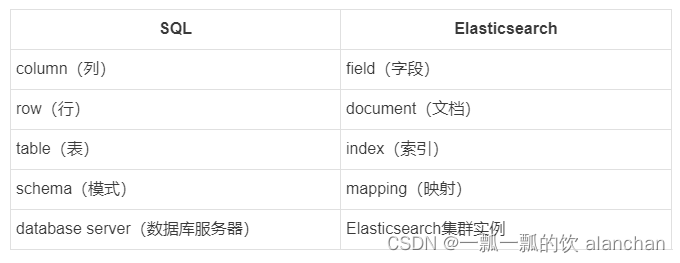
1、SQL与Elasticsearch对应关系
2、Elasticsearch SQL语法
目前FROM只支持单表
SELECT select_expr [, ...]
[ FROM table_name ]
[ WHERE condition ]
[ GROUP BY grouping_element [, ...] ]
[ HAVING condition]
[ ORDER BY expression [ ASC | DESC ] [, ...] ]
[ LIMIT [ count ] ][
PIVOT ( aggregation_expr FOR column IN ( value [ [ AS ] alias ] [, ...] ) ) ]
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
3、示例
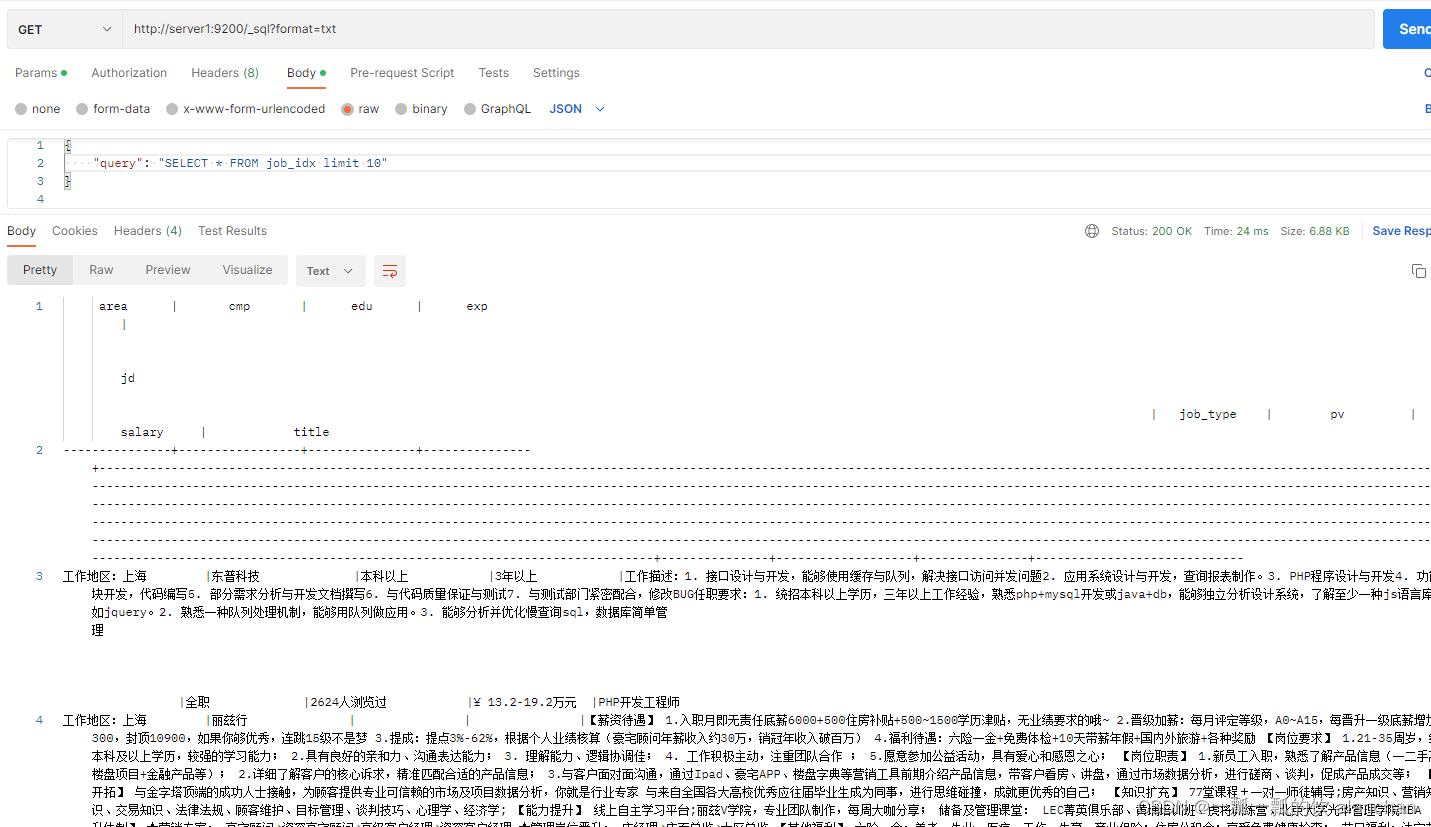
1)、查询职位索引库中的一条数据
format:表示指定返回的数据类型
// 1. 查询职位信息
GET /_sql?format=txt
{
"query": "SELECT * FROM job_idx limit 1"
}
- 1
- 2
- 3
- 4
- 5
除了txt类型,Elasticsearch SQL还支持以下类型
// 1. 查询职位信息
GET /_sql?format=json
{
"query": "SELECT * FROM job_idx limit 10"
}
- 1
- 2
- 3
- 4
- 5
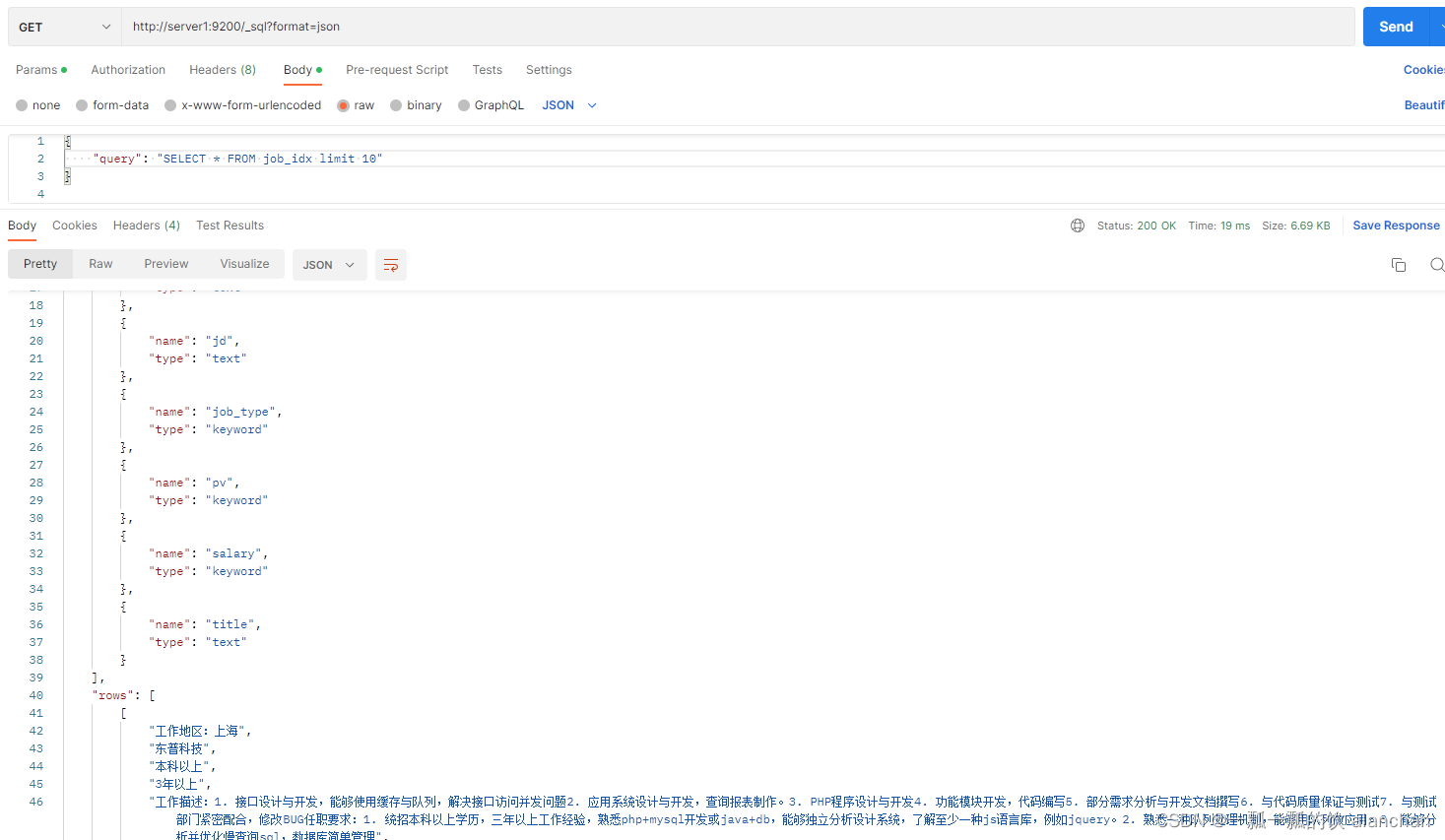
2)、将SQL转换为DSL
GET /_sql/translate
{
"query": "SELECT * FROM job_idx limit 1"
}
- 1
- 2
- 3
- 4
查询结果如下:
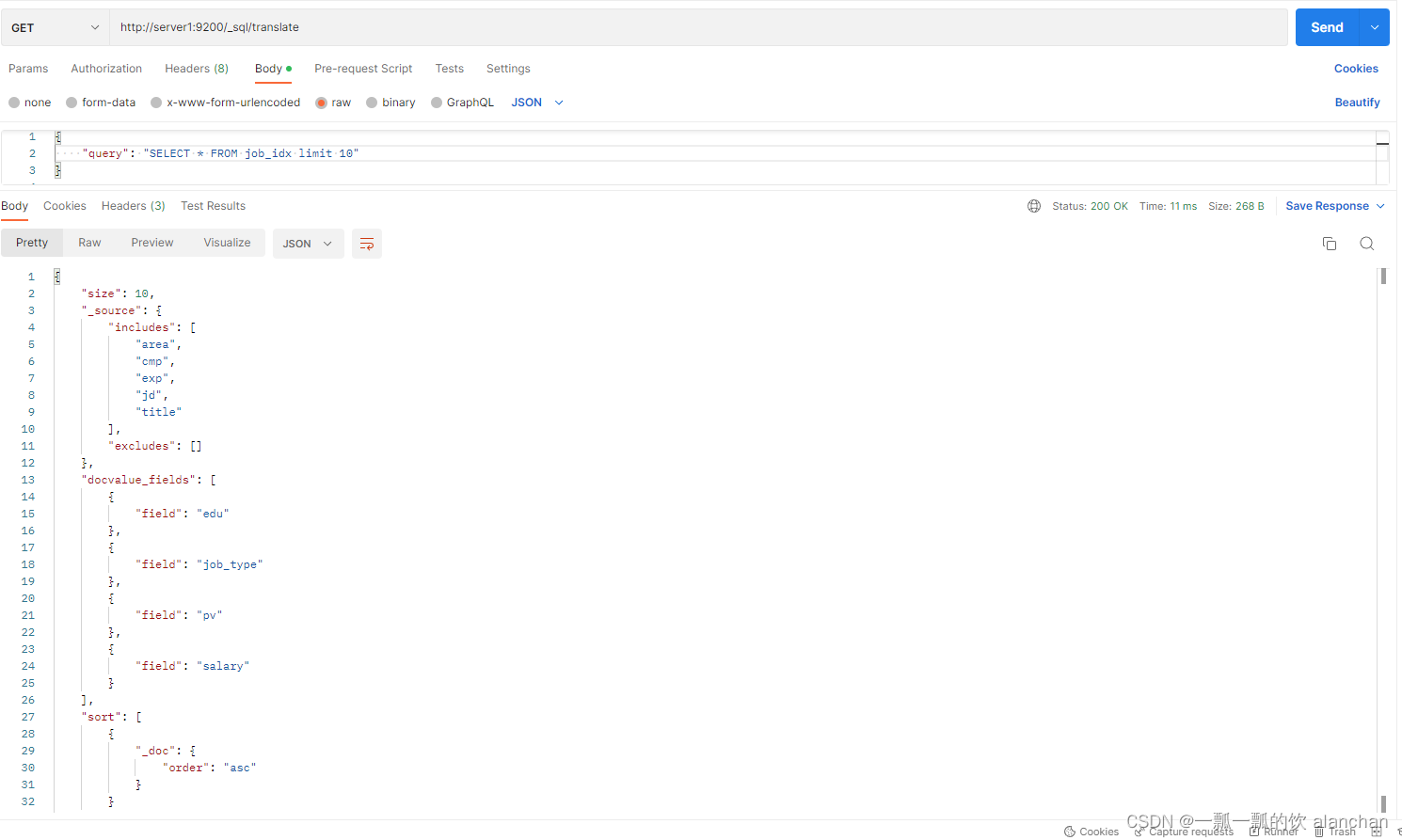
3)、职位scroll分页查询
第一次查询
// 2. scroll分页查询
GET /_sql?format=json
{
"query": "SELECT * FROM job_idx",
"fetch_size": 10
}
fetch_size表示每页显示多少数据,而且当我们指定format为Json格式时,会返回一个cursor ID
{
"columns": [
{ "name": "area", "type": "text" },
{ "name": "cmp", "type": "text" },
{ "name": "edu", "type": "keyword" },
{ "name": "exp", "type": "text" },
{ "name": "jd", "type": "text" },
{ "name": "job_type", "type": "keyword" },
{ "name": "pv", "type": "keyword" },
{ "name": "salary", "type": "keyword" },
{ "name": "title", "type": "text" }
],
"rows": [
[
"工作地区:上海",
"东普科技",
"本科以上",
"3年以上",
"工作描述:1. 接口设计与开发,能够使用缓存与队列,解决接口访问并发问题2. 应用系统设计与开发,查询报表制作。3. PHP程序设计与开发4. 功能模块开发,代码编写5. 部分需求分析与开发文档撰写6. 与代码质量保证与测试7. 与测试部门紧密配合,修改BUG任职要求:1. 统招本科以上学历,三年以上工作经验,熟悉php+mysql开发或java+db,能够独立分析设计系统,了解至少一种js语言库,例如jquery。2. 熟悉一种队列处理机制,能够用队列做应用。3. 能够分析并优化慢查询sql,数据库简单管理",
"全职",
"2624人浏览过",
"¥ 13.2-19.2万元",
"PHP开发工程师"
],
[
。。。
],
[
。。。
],
[
。。。
],
[
。。。
]
],
"cursor": "5/WuAwFaAXNARFhGMVpYSjVRVzVrUm1WMFkyZ0JBQUFBQUFBQUFCMFdUbkZuYTBJMVYyWlJia05IVFhsU2JsOVlUVEYyVVE9Pf8PCQFmBGFyZWEBBGFyZWEBBHRleHQAAAABZgNjbXABA2NtcAEEdGV4dAAAAAFmA2VkdQEDZWR1AQdrZXl3b3JkAQAAAWYDZXhwAQNleHABBHRleHQAAAABZgJqZAECamQBBHRleHQAAAABZghqb2JfdHlwZQEIam9iX3R5cGUBB2tleXdvcmQBAAABZgJwdgECcHYBB2tleXdvcmQBAAABZgZzYWxhcnkBBnNhbGFyeQEHa2V5d29yZAEAAAFmBXRpdGxlAQV0aXRsZQEEdGV4dAAAAAL/AQ=="
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
默认快照的失效时间为45s,如果要延迟快照失效时间,可以配置为以下:
GET /_sql?format=json
{
"query": "select * from job_idx",
"fetch_size": 1000,
"page_timeout": "10m"
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
第二次查询
GET /_sql?format=json
{
"cursor": "5/WuAwFaAXNARFhGMVpYSjVRVzVrUm1WMFkyZ0JBQUFBQUFBQUFCMFdUbkZuYTBJMVYyWlJia05IVFhsU2JsOVlUVEYyVVE9Pf8PCQFmBGFyZWEBBGFyZWEBBHRleHQAAAABZgNjbXABA2NtcAEEdGV4dAAAAAFmA2VkdQEDZWR1AQdrZXl3b3JkAQAAAWYDZXhwAQNleHABBHRleHQAAAABZgJqZAECamQBBHRleHQAAAABZghqb2JfdHlwZQEIam9iX3R5cGUBB2tleXdvcmQBAAABZgJwdgECcHYBB2tleXdvcmQBAAABZgZzYWxhcnkBBnNhbGFyeQEHa2V5d29yZAEAAAFmBXRpdGxlAQV0aXRsZQEEdGV4dAAAAAL/AQ=="
}
- 1
- 2
- 3
- 4
4)、清除游标
POST /_sql/close
{
"cursor": "5/WuAwFaAXNARFhGMVpYSjVRVzVrUm1WMFkyZ0JBQUFBQUFBQUFCNFdUbkZuYTBJMVYyWlJia05IVFhsU2JsOVlUVEYyVVE9Pf8PCQFmBGFyZWEBBGFyZWEBBHRleHQAAAABZgNjbXABA2NtcAEEdGV4dAAAAAFmA2VkdQEDZWR1AQdrZXl3b3JkAQAAAWYDZXhwAQNleHABBHRleHQAAAABZgJqZAECamQBBHRleHQAAAABZghqb2JfdHlwZQEIam9iX3R5cGUBB2tleXdvcmQBAAABZgJwdgECcHYBB2tleXdvcmQBAAABZgZzYWxhcnkBBnNhbGFyeQEHa2V5d29yZAEAAAFmBXRpdGxlAQV0aXRsZQEEdGV4dAAAAAL/AQ=="
}
- 1
- 2
- 3
- 4
5)、职位全文检索
检索title和jd中包含hadoop的职位
在执行全文检索时,需要使用到MATCH函数
MATCH(field_exp,constant_exp[, options])
field_exp:匹配字段
constant_exp:匹配常量表达式
GET /_sql?format=txt
{
"query": "select * from job_idx where MATCH(title, 'hadoop') or MATCH(jd, 'hadoop') limit 10"
}
- 1
- 2
- 3
- 4
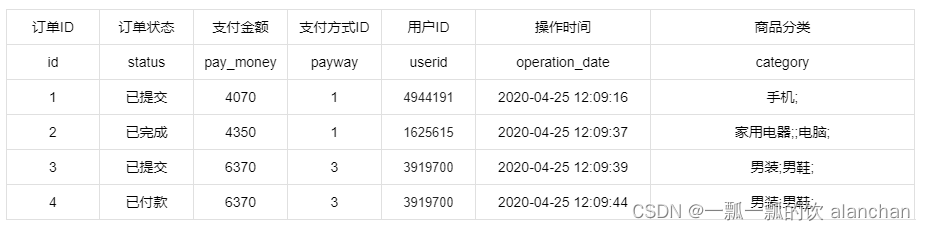
6)、订单统计分析案例
基于按数据,使用Elasticsearch中的聚合统计功能
1、创建索引
PUT /order_idx/
{
"mappings": {
"properties": {
"id": {
"type": "keyword",
"store": true
},
"status": {
"type": "keyword",
"store": true
},
"pay_money": {
"type": "double",
"store": true
},
"payway": {
"type": "byte",
"store": true
},
"userid": {
"type": "keyword",
"store": true
},
"operation_date": {
"type": "date",
"format": "yyyy-MM-dd HH:mm:ss",
"store": true
},
"category": {
"type": "keyword",
"store": true
}
}
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
2、导入测试数据
curl -H "Content-Type: application/json" -XPOST "server1:9200/order_idx/_bulk?pretty&refresh" --data-binary "@order_data.json"
- 1
3、统计不同支付方式的的订单数量
- 使用JSON DSL的方式来实现
用Elasticsearch原生支持的基于JSON的DSL方式来实现聚合统计
GET /order_idx/_search
{
"size": 0,
"aggs": {
"group_by_state": {
"terms": {
"field": "payway"
}
}
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
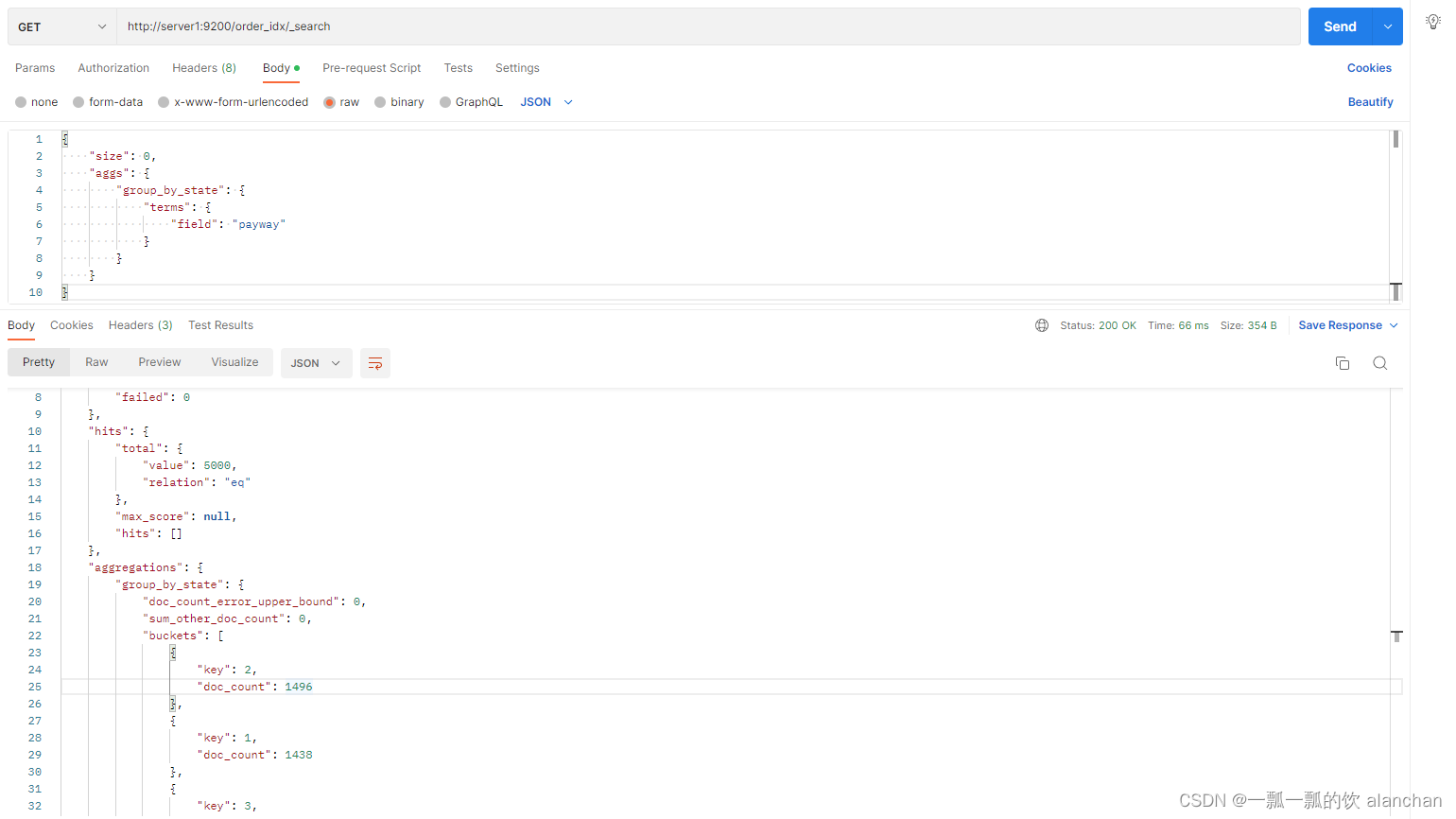
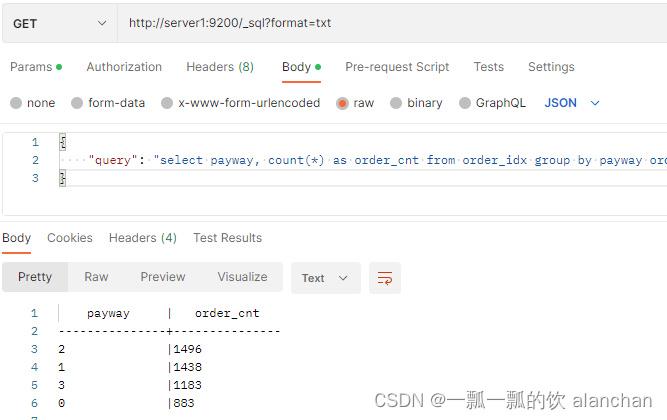
这种方式分析起来比较麻烦。ES也能够使用SQL方式来进行统计和分析的
- 基于Elasticsearch SQL方式实现
ET /_sql?format=txt
{
"query": "select payway, count(*) as order_cnt from order_idx group by payway"
}
- 1
- 2
- 3
- 4
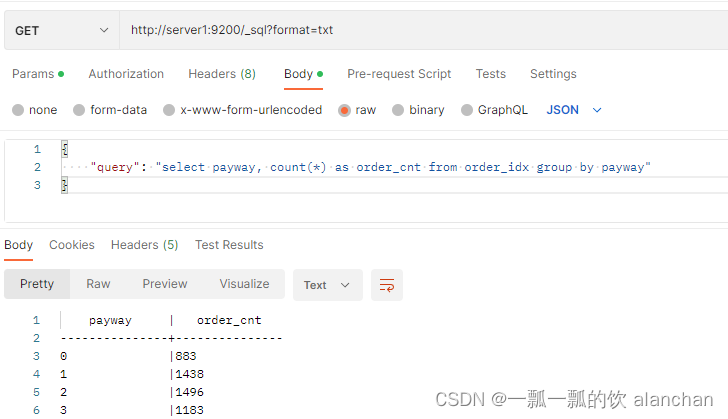
- 基于JDBC方式统计不同方式的订单数量
pom.xml
该版本在maven上没有,需要使用阿里的镜像库
<dependency>
<groupId>org.elasticsearch.plugin</groupId>
<artifactId>x-pack-sql-jdbc</artifactId>
<version>7.6.1</version>
</dependency>
- 1
- 2
- 3
- 4
- 5
开启X-pack高阶功能试用,如果不开启试用,会报如下错误
current license is non-compliant for [jdbc]
在server1节点上执行:
查看服务器es的license信息,发现 “type” : “basic”
# curl -XGET http://server1:9200/_license
{
"license" : {
"status" : "active",
"uid" : "91546f48-bd7f-4a74-b4b9-889dece7db80",
"type" : "basic",
"issue_date" : "2020-05-12T20:10:42.742Z",
"issue_date_in_millis" : 1589314242742,
"max_nodes" : 1000,
"issued_to" : "my-application",
"issuer" : "elasticsearch",
"start_date_in_millis" : -1
}
}
#修改成30天试用版,https://www.elastic.co/guide/en/elasticsearch/reference/master/start-trial.html
curl http://server1:9200/_license/start_trial?acknowledge=true -X POST {"acknowledged":true,"trial_was_started":true,"type":"trial"}
试用期为30天。
[alanchan@server1 testdata]$ curl http://server1:9200/_license/start_trial?acknowledge=true -X POST {"acknowledged":true,"trial_was_started":true,"type":"trial"}
curl: (6) Couldn't resolve host 'acknowledged:true'
curl: (6) Couldn't resolve host 'trial_was_started:true'
curl: (6) Couldn't resolve host 'type:trial'
{"acknowledged":true,"trial_was_started":true,"type":"trial"}
[alanchan@server1 testdata]$
#再查看license信息时,内容已发生变化
# curl -XGET http://localhost:9200/_license
{
"license" : {
"status" : "active",
"uid" : "275f23b1-7b57-4bfd-b309-16d9545aebfa",
"type" : "trial",
"issue_date" : "2020-05-14T03:16:54.139Z",
"issue_date_in_millis" : 1589426214139,
"expiry_date" : "2020-06-13T03:16:54.139Z",
"expiry_date_in_millis" : 1592018214139,
"max_nodes" : 1000,
"issued_to" : "my-application",
"issuer" : "elasticsearch",
"start_date_in_millis" : -1
}
}
[alanchan@server1 testdata]$
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
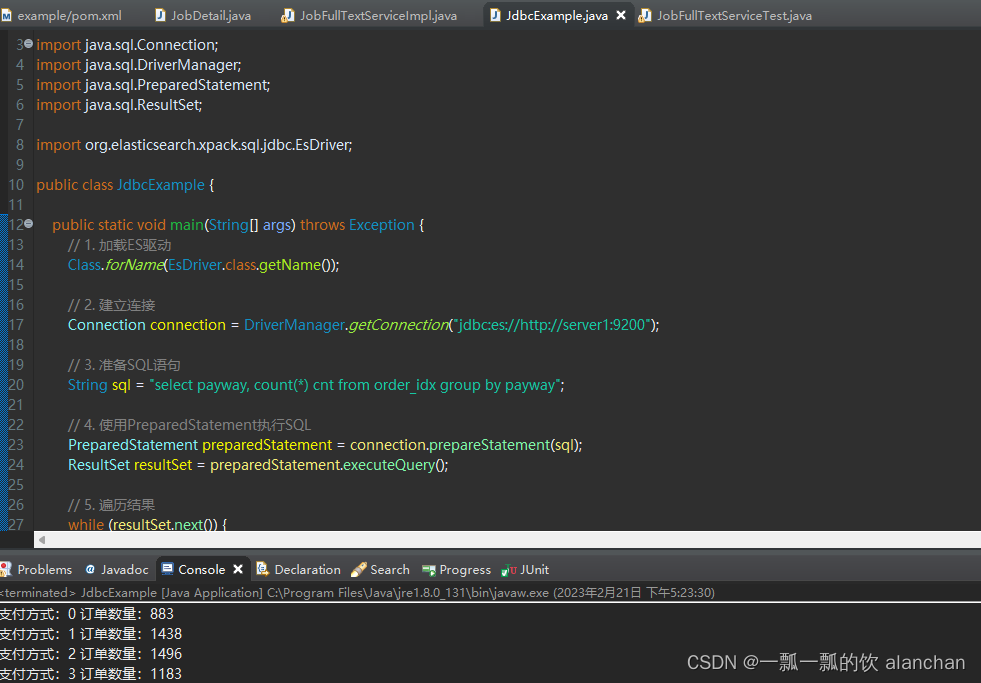
- 源码
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
import org.elasticsearch.xpack.sql.jdbc.EsDriver;
public class JdbcExample {
public static void main(String[] args) throws Exception {
// 1. 加载ES驱动
Class.forName(EsDriver.class.getName());
// 2. 建立连接
Connection connection = DriverManager.getConnection("jdbc:es://http://server1:9200");
// 3. 准备SQL语句
String sql = "select payway, count(*) cnt from order_idx group by payway";
// 4. 使用PreparedStatement执行SQL
PreparedStatement preparedStatement = connection.prepareStatement(sql);
ResultSet resultSet = preparedStatement.executeQuery();
// 5. 遍历结果
while (resultSet.next()) {
byte payway = resultSet.getByte("payway");
long cnt = resultSet.getLong("cnt");
System.out.println("支付方式:" + payway + " 订单数量:" + cnt);
}
// 6. 关闭连接
resultSet.close();
connection.close();
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 运行结果
4、统计不同支付方式订单数,并按照订单数量倒序排序
GET /_sql?format=txt
{
"query": "select payway, count(*) as order_cnt from order_idx group by payway order by order_cnt desc"
}
- 1
- 2
- 3
- 4
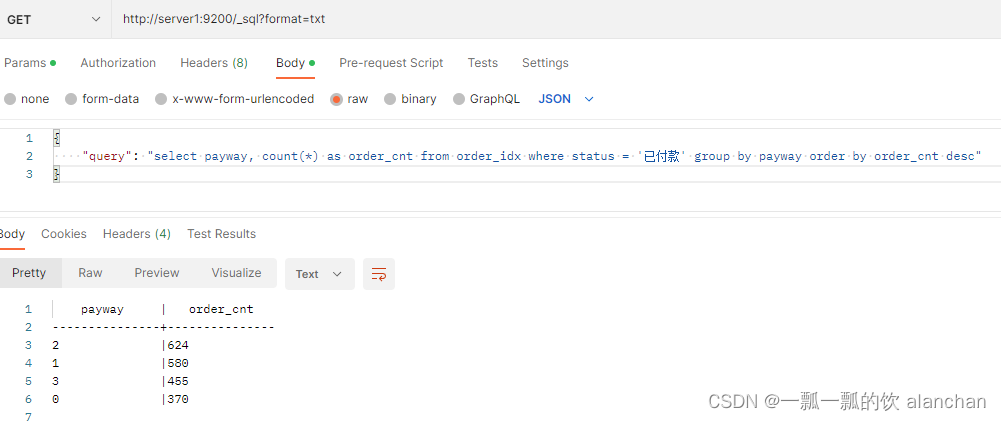
5、只统计「已付款」状态的不同支付方式的订单数量
GET /_sql?format=txt
{
"query": "select payway, count(*) as order_cnt from order_idx where status = '已付款' group by payway order by order_cnt desc"
}
- 1
- 2
- 3
- 4
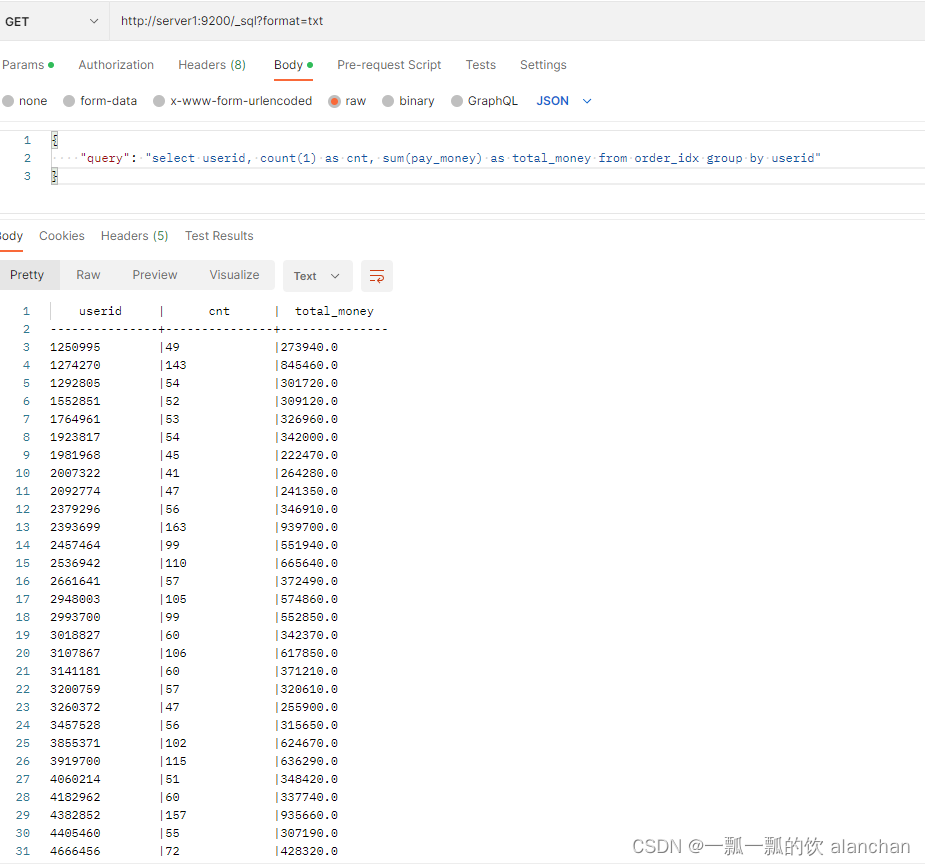
6、统计不同用户的总订单数量、总订单金额
GET /_sql?format=txt
{
"query": "select userid, count(1) as cnt, sum(pay_money) as total_money from order_idx group by userid"
}
- 1
- 2
- 3
- 4
4、Elasticsearch SQL目前的一些限制
目前Elasticsearch SQL还存在一些限制。
例如:不支持JOIN、不支持较复杂的子查询。所以,有一些相对复杂一些的功能,还得借助于DSL方式来实现
以上,简单的介绍了java api操作Elasticsearch和Elasticsearch SQL的详细示例。